AI automat pro třídění zákaznických dotazů a návrhy odpovědí
Zákaznická podpora bývá jedním z prvních procesů, kde se umělá inteligence vyplatí prakticky a rychle. Typický tým podpory denně řeší desítky až stovky opakujících se dotazů: změny fakturačních údajů, stav objednávky, vrácení zboží, technické potíže, reklamace nebo žádosti o eskalaci. Právě zde dává smysl nasadit AI tak, aby nejprve dotaz roztřídila, následně navrhla odpověď a v rizikových případech předala ticket člověku.
Tento návod ukazuje realizovatelný postup pro MVP projektu, které lze nasadit bez rozsáhlého vývoje. Cílem není plně autonomní support bez lidí, ale funkční kombinace automatizace a kontroly: AI pomáhá s tříděním a návrhem odpovědí, zatímco operátor schvaluje nebo řeší výjimky. Postup je navržen tak, aby po dokončení jednotlivých kroků vznikl provozuschopný základ nad reálnými službami.
Úvod

V praxi má AI v support workflow největší přínos ve třech bodech. Za prvé zkrátí čas od přijetí dotazu k jeho zařazení. Za druhé sjednotí kvalitu odpovědí, protože návrh vychází z připravených pravidel a interní znalostní báze. Za třetí pomůže s eskalací tam, kde je vyšší riziko chyby: například u právních sporů, vratky po lhůtě, VIP zákazníků nebo incidentů se službou.
Dobře navržené MVP musí zvládnout několik konkrétních úloh: přečíst příchozí text, přiřadit kategorii, určit prioritu, rozpoznat jazyk, navrhnout odpověď a rozhodnout, zda je bezpečné odpovědět automaticky, nebo zda je nutná eskalace. K tomu je potřeba nejen model, ale i data, pravidla a integrace do ticketovacího systému.
Cíl projektu
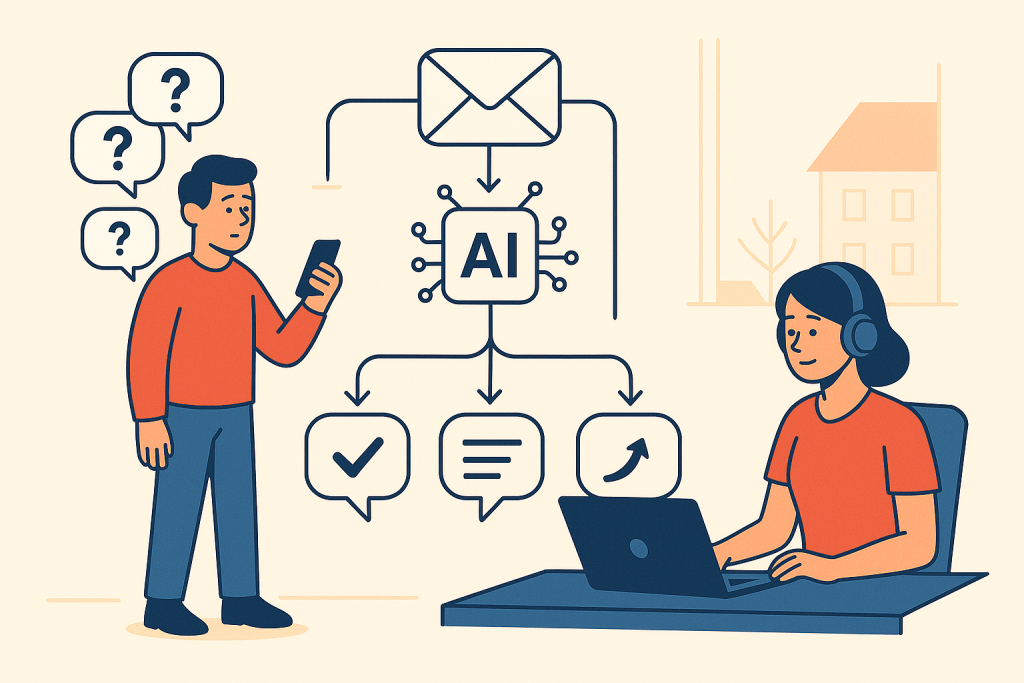
Cílem projektu je vytvořit minimálně životaschopné řešení, které po přijetí zákaznického dotazu v systému Zendesk provede následující:
- určí kategorii dotazu, například fakturace, vrácení zboží, technický problém, stav objednávky,
- vyhodnotí prioritu a doporučí frontu nebo tým,
- vygeneruje návrh odpovědi v češtině,
- označí případy, které mají být eskalovány člověku,
- zapíše výsledek zpět do ticketu jako interní poznámku a volitelně předvyplní odpověď operátorovi.
Za úspěch MVP lze považovat stav, kdy systém automaticky správně zařadí většinu běžných dotazů, zkrátí čas první reakce a nesníží kvalitu obsluhy. Rozumný počáteční cíl je například přesnost třídění nad 80 % na vybraných kategoriích a zkrácení času první reakce o 30 %. Pokud ve vašem prostředí takové hodnoty zatím nejsou dosažitelné, je to omezení projektu, nikoli chyba metodiky.
Předpoklady
Než začnete, připravte si prostředí a minimální vstupy. V tomto návodu budeme používat:
- Zendesk Support pro práci s tickety,
- Zapier pro automatizaci bez vlastního backendu,
- OpenAI API pro klasifikaci a návrh odpovědi,
- Google Sheets pro evidenci kategorií, pravidel a testovacích dat.
Budete potřebovat administrátorský přístup alespoň do části nastavení. Dále si připravte:
- historii alespoň 200 až 500 anonymizovaných ticketů,
- seznam kategorií a front,
- základní firemní pravidla pro odpovědi, například tón komunikace, lhůty a zakázané formulace,
- API klíče pro OpenAI a integraci do Zendesku.
Pokud historii ticketů nemáte, lze MVP spustit i s menším vzorkem, ale přesnost třídění bude pravděpodobně nižší. To je vhodné explicitně vnímat jako limit pilotního provozu.
Kroky realizace
Krok 1: Vymezte kategorie, priority a pravidla eskalace
Co a proč: Než zapojíte AI, musíte přesně určit, co má systém vracet. Bez stabilních kategorií a pravidel bude model sice odpovídat, ale výsledky nepůjdou spolehlivě použít v provozu. Prvním cílem je vytvořit jednoduché schéma, podle kterého se bude každý ticket zpracovávat.
Jak přesně: V Google Sheets vytvořte list support_taxonomie se sloupci kategorie, priorita_default, eskalace_podminka, cilovy_tym, auto_reply_allowed. Vyplňte například tyto řádky:
kategorie,priorita_default,eskalace_podminka,cilovy_tym,auto_reply_allowed
stav_objednavky,nizka,nikdy,customer_care,ano
fakturace,stredni,pokud obsahuje zadost o dobropis,billing,ano
vraceni_zbozi,stredni,pokud po lhute nebo spor,returns,ano
technicky_problem,vysoka,pokud vypadek nebo vice zakazniku,tech_support,ne
pravni_stiznost,kriticka,vzdy,legal,neV Zendesku v menu Admin Center → Objects and rules → Tickets → Fields založte vlastní pole:
ai_categorytypu dropdown,ai_prioritytypu dropdown,ai_escalatetypu checkbox,ai_draft_replytypu multiline text.
Konkrétní vstup: sloupec eskalace_podminka s hodnotou pokud po lhute nebo spor.
Konkrétní výstup: seznam pěti až deseti kategorií a odpovídajících pravidel použitelných v automatizaci.
Metrika úspěšnosti: 100 % historických ticketů lze ručně zařadit do právě jedné kategorie nebo do výjimky ostatni. Pokud to nejde, taxonomie je zatím příliš nejasná.
Tím jste vytvořili rámec, podle kterého budou další kroky fungovat konzistentně. Nyní je potřeba připravit data, na nichž ověříte, že zvolená schémata dávají smysl.
Krok 2: Připravte historická data a označte vzorek ticketů
Co a proč: I když v tomto MVP nebudete trénovat vlastní model, potřebujete testovací a validační sadu. Bez ní nezjistíte, zda AI třídí správně, ani kde přesně chybuje.
Jak přesně: V Zendesku exportujte historické tickety přes Admin Center → Accounts → Tools → Reports → Export data, případně využijte oficiální exportní možnosti dostupné ve vašem tarifu. Do Google Sheets nebo CSV přeneste alespoň sloupce:
ticket_id,subject,description,created_at,brand,locale,final_group,manual_category.
Poté ručně označte alespoň 150 ticketů ve sloupci manual_category podle taxonomie z kroku 1. Pro anonymizaci odstraňte osobní údaje. Jednoduchá akce v tabulce je nahrazení e-mailů výrazem [EMAIL] a telefonních čísel výrazem [TEL].
Ukázka vstupu:
ticket_id: 58421
subject: Faktura k objednávce 2024-1198
description: Dobrý den, na faktuře chybí moje IČO a potřebuji ji opravit.
locale: csOčekávaný výstup po označení:
manual_category: fakturace
expected_priority: stredni
expected_escalation: neKonkrétní vstup: pole description.
Konkrétní výstup: sloupce manual_category, expected_priority, expected_escalation.
Metrika úspěšnosti: alespoň 150 ručně označených ticketů, z nichž minimálně 20 připadá na každou hlavní kategorii. Pokud je rozdělení velmi nerovnoměrné, budou výsledky pilotu zkreslené.
Když máte data a referenční pravdu, můžete navrhnout samotnou AI logiku tak, aby vracela strukturované hodnoty použitelné v Zendesku a Zapieru.
Krok 3: Navrhněte strukturovaný prompt pro klasifikaci a eskalaci
Co a proč: Pro support workflow je zásadní, aby model nevracel volný text, ale předvídatelnou strukturu. To zjednoduší automatizaci i audit. V tomto kroku vytvoříte prompt, který z jednoho ticketu získá kategorii, prioritu, důvod a doporučení eskalace.
Jak přesně: V platformě OpenAI použijte endpoint Responses API. V Zapieru následně nastavíte akci OpenAI, ale nejprve si prompt odlaďte ručně. Použijte například tento vstupní formát:
System:
Jsi asistent pro zákaznickou podporu e-shopu. Zařaď dotaz pouze do jedné z kategorií:
- stav_objednavky
- fakturace
- vraceni_zbozi
- technicky_problem
- pravni_stiznost
- ostatni
Urči prioritu: nizka | stredni | vysoka | kriticka.
Urči eskalaci: ano | ne.
Eskaluj vždy při právní stížnosti, hrozbě sporu, výpadku služby, více postižených zákaznících nebo pokud chybí dost informací pro bezpečnou odpověď.
Vrať pouze JSON se strukturou:
{
"category": "",
"priority": "",
"escalate": "",
"reason": ""
}
User:
subject: Faktura k objednávce 2024-1198
description: Dobrý den, na faktuře chybí moje IČO a potřebuji ji opravit.
locale: cs
brand: Hlavní e-shopOčekávaný výstup:
{
"category": "fakturace",
"priority": "stredni",
"escalate": "ne",
"reason": "Zákazník žádá opravu fakturačních údajů, nejde o spor ani právní stížnost."
}Pokud používáte přímé API volání, relevantní parametr bude například model s hodnotou gpt-4.1-mini. Konkrétní dostupnost modelu je třeba ověřit v aktuální dokumentaci OpenAI; pokud se nabídka změní, jde o provozní omezení, které může vyžadovat náhradu obdobným modelem.
Konkrétní vstup: pole subject, description, locale.
Konkrétní výstup: JSON s klíči category, priority, escalate, reason.
Metrika úspěšnosti: alespoň 95 % odpovědí lze bez chyby parseovat jako validní JSON. Pokud ne, prompt je potřeba zpřísnit.
Jakmile klasifikace vrací stabilní strukturu, můžete na ni navázat druhý krok AI: návrh odpovědi pro operátora nebo přímé použití v bezpečných případech.
Krok 4: Přidejte generování návrhu odpovědi podle firemních pravidel
Co a proč: Samotné roztřídění šetří čas, ale největší provozní efekt často přinese návrh odpovědi. Důležité je, aby odpověď vycházela z interních pravidel a nebyla příliš sebevědomá tam, kde chybí data.
Jak přesně: V Google Sheets vytvořte list knowledge_base se sloupci category, policy_summary, allowed_actions, forbidden_claims, template_reply. Pro kategorii vraceni_zbozi můžete zapsat například:
category: vraceni_zbozi
policy_summary: Standardní vrácení do 14 dnů od převzetí, nepoužité zboží.
allowed_actions: poslat odkaz na formulář, vyžádat číslo objednávky
forbidden_claims: neslibovat výjimku po lhůtě bez schválení
template_reply: Dobrý den, děkujeme za zprávu. Pro vrácení zboží prosím pošlete číslo objednávky a vyplňte formulář na adrese ...V promptu pro odpověď pak kombinujte výstup klasifikace a odpovídající záznam z tabulky:
System:
Jsi asistent zákaznické podpory. Piš česky, stručně a zdvořile. Dodrž policy_summary a forbidden_claims. Pokud si nejsi jistý, napiš, že požadavek předáváme specialistovi.
Vrať JSON:
{
"draft_reply": "",
"needs_human_review": true,
"used_policy": ""
}
User:
category: fakturace
policy_summary: Oprava IČO a DIČ na faktuře je možná po ověření čísla objednávky.
forbidden_claims: neslibovat okamžité vystavení bez ověření
subject: Faktura k objednávce 2024-1198
description: Dobrý den, na faktuře chybí moje IČO a potřebuji ji opravit.Očekávaný výstup:
{
"draft_reply": "Dobrý den, děkujeme za zprávu. Opravu fakturačních údajů můžeme provést po ověření objednávky. Prosím pošlete číslo objednávky a správné IČO, případně DIČ.",
"needs_human_review": true,
"used_policy": "Oprava IČO a DIČ na faktuře je možná po ověření čísla objednávky."
}Konkrétní vstup: sloupec forbidden_claims s hodnotou neslibovat okamžité vystavení bez ověření.
Konkrétní výstup: pole draft_reply připravené k vložení do ticketu.
Metrika úspěšnosti: při ručním auditu 50 odpovědí neobsahuje více než 5 % návrhů tvrzení, která odporují interním pravidlům.
Nyní už máte dva základní AI moduly. Dalším logickým krokem je propojit je s reálným ticketem tak, aby vše probíhalo automaticky po jeho vytvoření.
Krok 5: Sestavte workflow v Zapieru mezi Zendeskem a OpenAI
Co a proč: V tomto kroku se z jednotlivých částí stane fungující proces. Zapier zajistí, že po vytvoření ticketu zavolá OpenAI, zpracuje výstup a zapíše jej zpět do Zendesku.
Jak přesně: V Zapieru vytvořte nový Zap. Jako trigger zvolte Zendesk → New Ticket. Ověřte připojení k účtu a vyberte testovací ticket. Poté přidejte akci Formatter by Zapier → Text, kde zkrátíte příliš dlouhý text, například na 4000 znaků. Následně přidejte akci OpenAI pro klasifikaci a druhou akci OpenAI pro návrh odpovědi.
Příklad konkrétního mapování vstupů v Zapu:
subject← Zendesk Ticket Subjectdescription← Zendesk Descriptionlocale← Zendesk Localebrand← Zendesk Brand Name
Po obou AI krocích přidejte akci Zendesk → Update Ticket a namapujte:
Custom Field: ai_category←categoryCustom Field: ai_priority←priorityCustom Field: ai_escalate←escalateInternal Note← důvod klasifikace + návrh odpovědi
Krátký příklad interní poznámky:
AI klasifikace: fakturace
Priorita: střední
Eskalace: ne
Důvod: Zákazník žádá opravu fakturačních údajů.
Návrh odpovědi: Dobrý den, děkujeme za zprávu...Konkrétní vstup: trigger New Ticket a pole Description.
Konkrétní výstup: aktualizovaný ticket s vyplněnými poli ai_category, ai_priority, ai_escalate a interní poznámkou.
Metrika úspěšnosti: minimálně 90 % testovacích ticketů projde celým Zapem bez technické chyby. Pokud ne, nejčastěji bývá problém v prázdných polích, délce textu nebo formátu JSON.
Automatické zpracování již funguje, ale stále chybí provozní logika, co se má stát při eskalaci, a jak odlišit bezpečné automatické případy od rizikových.
Krok 6: Zaveďte pravidla pro automatické přiřazení a eskalaci
Co a proč: AI nemá jen navrhnout odpověď, ale také rozhodnout, kdy ji nepoužít bez kontroly. Tento krok přidá provozní pojistku, která minimalizuje riziko chybných odpovědí.
Jak přesně: V Zendesku otevřete Admin Center → Objects and rules → Business rules → Triggers a vytvořte trigger například s názvem AI eskalace do specializované fronty. Nastavte podmínky:
Ticket: AI eskalacejechecked,Statusnenísolved.
Akce mohou být například:
Group=Tech Support, pokudai_category = technicky_problem,Priority=high, pokudai_priority = vysoka,Add tags=ai_escalated.
Současně vytvořte druhý trigger pro bezpečné případy, například AI návrh odpovědi pro operátora, který při ai_escalate = false pouze přidá interní poznámku a nezašle odpověď zákazníkovi automaticky. Plně automatické odesílání doporučuji v MVP zapnout jen u velmi omezené skupiny dotazů, například stav_objednavky, pokud máte ověřená data ze systému objednávek. Bez takového napojení je bezpečnější zůstat u návrhu odpovědi.
Příklad pravidla rozhodnutí:
if category == "pravni_stiznost" then escalate = ano
if description contains "ČOI" or "právník" then escalate = ano
if category == "stav_objednavky" and missing_order_id then escalate = anoKonkrétní vstup: hodnota pole ai_escalate a tag ai_escalated.
Konkrétní výstup: ticket přiřazený do správné skupiny, s prioritou a interní poznámkou pro operátora.
Metrika úspěšnosti: 100 % ticketů označených jako pravni_stiznost nebo s výrazem ČOI je eskalováno člověku. Tato metrika má přednost před rychlostí.
Teď už máte funkční MVP workflow. Aby bylo použitelné v běžném provozu, je potřeba jej změřit na historických i nových datech a určit, kde se na něj lze spolehnout a kde ne.
Krok 7: Vyhodnoťte přesnost na testovací sadě a dolaďte pravidla
Co a proč: Před nasazením do živého provozu musíte porovnat výstupy AI s ručně označenou sadou. Tím zjistíte nejen celkovou přesnost, ale hlavně problematické kategorie a časté důvody chyb.
Jak přesně: V Zapieru nebo skriptem pošlete 150 označených ticketů přes stejné workflow jako v provozu a výsledky zapisujte do Google Sheets do listu evaluation se sloupci ticket_id, manual_category, ai_category, manual_escalation, ai_escalation, reply_ok, notes.
V tabulce pak vytvořte jednoduché vzorce. Například pro přesnost kategorií:
=COUNTIF(H2:H151;TRUE)/COUNTA(A2:A151)Kde sloupec H obsahuje logickou hodnotu, zda manual_category = ai_category.
Příklad vstupu a očekávaného výstupu hodnocení:
Vstup:
manual_category = vraceni_zbozi
ai_category = vraceni_zbozi
manual_escalation = ne
ai_escalation = ano
Výstup:
category_match = ano
escalation_match = ne
notes = AI byla příliš opatrná kvůli chybějícímu číslu objednávky.Konkrétní vstup: sloupec manual_escalation.
Konkrétní výstup: vypočtené metriky accuracy_category, accuracy_escalation, reply_ok_rate.
Metrika úspěšnosti: cílově alespoň 80 % přesnost kategorií, 90 % zachycení povinných eskalací a 85 % použitelných návrhů odpovědí po lehké editaci operátorem.
Pokud výsledky nevyjdou, nevracejte se hned k úplné přestavbě. Nejprve upravte taxonomii, doplňte příklady do promptu a zpřesněte pravidla eskalace. Teprve poté má smysl uvažovat o složitější architektuře.
Doporučený AI stack pro realizaci
Vyberte nástroje podle rozpočtu a úrovně automatizace. Níže je přímý přehled služeb pro realizaci projektu.
| Tool | Offer |
|---|---|
| NordVPN | Otevřít nabídku |
| Semrush | Otevřít nabídku |
| Notion | Otevřít nabídku |
| Hostinger | Otevřít nabídku |
| Fiverr | Otevřít nabídku |
| Adobe | Otevřít nabídku |
| Canva | Otevřít nabídku |
| Jasper | Otevřít nabídku |
Testování
Testování rozdělte na tři vrstvy. První je technické: zda Zap doběhne, JSON je validní a pole se zapíší do Zendesku. Druhá je obsahová: zda klasifikace a návrhy odpovědí odpovídají interním pravidlům. Třetí je provozní: zda workflow skutečně šetří čas a nezvyšuje počet incidentů.
Praktický testovací plán pro MVP:
- Smoke test na 10 tiketech: ověřte propojení Zendesk → Zapier → OpenAI → Zendesk.
- Obsahový audit na 50 tiketech: dva lidé z podpory zhodnotí správnost kategorie a návrhu odpovědi.
- Pilot v omezeném provozu na jedné frontě, například fakturace a stav objednávky, po dobu jednoho týdne.
Sledujte konkrétní ukazatele:
- míra správně vyplněné kategorie,
- míra povinných eskalací zachycených AI,
- průměrný čas první reakce,
- podíl návrhů odpovědí použitých bez zásadní úpravy,
- počet stížností způsobených chybným návrhem AI.
Pokud se objeví chyba s vyšším dopadem, například nesprávná rada u reklamace nebo právní stížnosti, příslušnou kategorii dočasně přepněte na povinnou lidskou kontrolu.
Nasazení
Pro ostré nasazení zvolte postupné zavedení. Nejprve aktivujte jen interní poznámky a vyplnění polí, nikoli automatické odesílání odpovědí zákazníkům. Teprve po ověření výsledků můžete u vybraných bezpečných scénářů zvážit automatické odpovědi.
Doporučený rollout:
- Týden 1: pouze klasifikace a priorita.
- Týden 2: přidat návrh odpovědi jako interní poznámku.
- Týden 3: zapnout automatické směrování do front.
- Týden 4: zvažovat automatickou odpověď jen pro úzce vymezené dotazy.
V Zendesku si připravte dashboard nebo alespoň filtrované pohledy podle tagů ai_escalated a hodnot vlastních polí. V Google Sheets nebo BI nástroji evidujte týdenní přehled metrik. Důležité je, aby měl někdo konkrétní odpovědnost za revizi chyb a úpravy promptů. Bez této provozní role se kvalita časem obvykle zhoršuje.
Limity
Tento přístup má několik omezení, která je potřeba pojmenovat otevřeně.
- Model nezná interní systémy automaticky. Pokud návrh odpovědi závisí na stavu objednávky, skladu nebo platby, musíte tato data dodat integrací. Bez nich může AI pouze formulovat bezpečný návrh, nikoli potvrzovat fakta.
- Kvalita závisí na taxonomii a pravidlech. Pokud se kategorie překrývají nebo jsou neurčité, model bude chybovat i při dobrém promptu.
- Právní a citlivé případy vyžadují lidskou kontrolu. To není slabina MVP, ale správné bezpečnostní nastavení.
- Nabídka modelů a ceny API se mohou měnit. Je potřeba pravidelně kontrolovat oficiální dokumentaci a náklady.
- Bez průběžného auditu hrozí drift. Změní-li se typy dotazů nebo interní politika, prompt i pravidla je nutné aktualizovat.
Pokud potřebujete vyšší přesnost, dalším krokem bývá napojení na interní znalostní bázi a transakční systémy, případně pokročilejší orchestrace mimo Zapier. To už ale přesahuje rámec tohoto MVP.
FAQ
Musím model trénovat na vlastních datech?
Pro toto MVP ne. Vystačíte si s kvalitním promptem, jasnou taxonomií a testovací sadou. Vlastní trénink nebo fine-tuning může pomoci později, ale není nutný pro první provozuschopnou verzi.
Lze odpovědi posílat zákazníkům zcela automaticky?
Ano, ale doporučit to lze jen u omezených a dobře ověřených scénářů. Bez napojení na interní data je bezpečnější používat AI jako návrh pro operátora.
Jaké minimum ticketů potřebuji pro pilot?
Praktické minimum je kolem 150 ručně označených ticketů pro vyhodnocení a 200 až 500 historických ticketů pro orientaci v typech dotazů. Menší vzorek je možný, ale výsledky budou méně spolehlivé.
Co když model vrací špatný formát JSON?
Nejprve zpřísněte prompt a přidejte požadavek na vrácení pouze JSON. Pokud problém trvá, vložte v Zapieru mezikrok pro validaci a fallback, například nastavení kategorie ostatni a povinnou eskalaci.
Jak poznám, že je návrh odpovědi dostatečně kvalitní?
Sledujte podíl odpovědí, které operátor použije bez zásadní editace, a počet incidentů způsobených nepřesným návrhem. Pro MVP je dobrým cílem, když alespoň 85 % návrhů stačí jen lehce upravit.
Závěr
Automatické třídění zákaznických dotazů, návrhy odpovědí a řízená eskalace pomocí AI patří mezi projekty, kde lze relativně rychle doručit hmatatelný výsledek. Klíčem není jen volba modelu, ale hlavně poctivě připravená taxonomie, jasná pravidla eskalace, strukturované výstupy a průběžný audit. Pokud postupujete po malých krocích, můžete během několika dnů až týdnů nasadit MVP, které v Zendesku automaticky vyplní kategorii, prioritu, navrhne odpověď a předá rizikové případy člověku.
Nejrozumnější strategie je začít konzervativně: AI jako pomocník operátora, ne jako nekontrolovaný autopilot. Jakmile získáte data o přesnosti a chování v provozu, můžete bezpečně rozšiřovat rozsah automatizace. Právě tato cesta obvykle vede k nejrychlejší návratnosti i k důvěře support týmu.
Doporučený další krok
Odkazy v článku
- Zendesk Support – oficiální nápověda
- Zendesk Developer Docs
- Zapier
- OpenAI
- Zendesk – produktové screenshoty a dokumentace
- Zapier
- NordVPN
- Semrush
- Hostinger
- Fiverr
- Adobe
- Canva
- Notion
- Jasper
Zdroje ilustračních obrázků
- Stock fotografie: zdroj
Vlastní ilustrační obrázek byl vytvořen pomocí OpenAI Images API.
| Služba | Popis služby | Nabídka |
|---|---|---|
| NordVPN | VPN služba pro ochranu soukromí a bezpečné připojení. | Otevřít nabídku |
| Semrush | SEO a marketingová platforma pro analýzu a růst návštěvnosti. | Otevřít nabídku |
| Make | Pokročilá vizuální automatizace workflow a integrací. | Otevřít nabídku |
| Hostinger | Webhosting a domény pro rychlé spuštění webu. | Otevřít nabídku |
| Fiverr | Marketplace pro freelancery a externí specialisty. | Otevřít nabídku |
| Adobe | Kreativní nástroje pro grafiku, video a digitální obsah. | Otevřít nabídku |
| Canva | Online design nástroj pro grafiku, prezentace a sociální sítě. | Otevřít nabídku |
| Jasper | AI nástroj pro marketingové texty a obsahové kampaně. | Otevřít nabídku |
Poznámka: U uvedených služeb používáme affiliate odkazy. Pokud přes ně provedete nákup, můžeme získat provizi bez navýšení ceny pro vás.